

Biweekly Malware Challenge #1: Gozi/ISFB String Decryption
Aim
The aim for this first challenge was to reverse engineer the string decryption routine to develop a script to automate decryption of the strings. This challenge could be completed without the use of disassembler specific plugins (e.g. IDA Python), and could simply involve patching the .BSS section of the unpacked payload with the decrypted strings, and proceeding to analyse the sample from there. That is the approach we will be taking in this write-up, as we will most likely be doing a lot more IDA Python stuff later.
Approach
As mentioned, there are at least two approaches you could have taken with this challenge; patch the strings within the context of a disassembler, or patch the entire section without using disassembler functionality, instead opening the file, locating the correct section, and overwriting it. We will be focusing on the second approach.
I chose to use unpac.me for unpacking this sample, as I didn’t have access to a virtual machine setup for dynamic analysis, and so it was as simple as uploading the sample, waiting for it to unpack, and downloading the unpacked payload. This particular packer is pretty simple though and can be unpacked through simple breakpoints on VirtualAlloc and VirtualProtect.
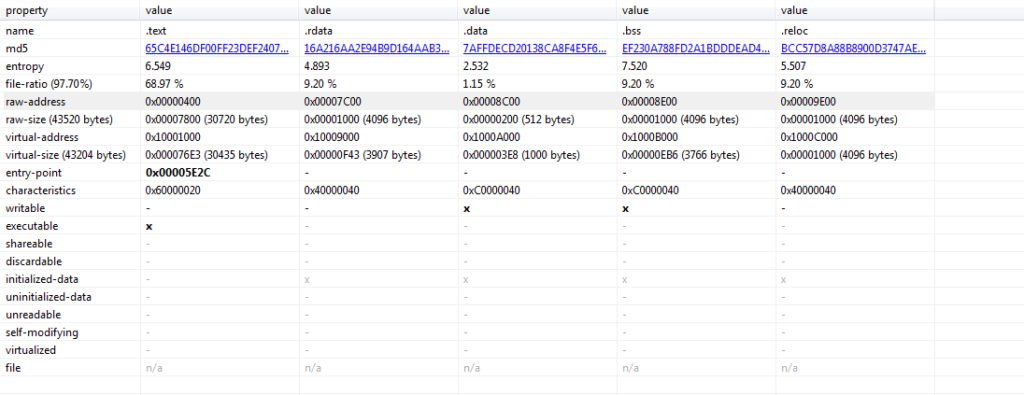
To successfully implement a script to decrypt all on-board strings, we need to understand how the strings are encrypted. So, we’ll start by opening the file up in PEStudio, to try and identify where encrypted strings may be present. This isn’t too necessary for every file you look at, but what we’ll be doing here is looking at the entropy for each PE section to gather some information on where encrypted strings may be stored. If that doesn’t help us, we’ll move straight over to looking at the sample in IDA (or any disassembler of your choice). At that point, we can search for calls to GetProcAddress. While not a 100% reliable method, if you can find calls to GetProcAddress within a sample, it is unlikely API hashing will be used, and possible that API names are encrypted using the string encryption routine.
If the above still fails, we can scour large undefined regions of data within the disassembled binary looking for blobs of incomprehensible data with cross references within the code sections. Luckily, we won’t need to do this for the sample, but if you do ever find yourself going in circles trying to find encrypted strings, this should be a decent method to locate them.
Analysis
Dragging the sample into PEStudio, we can see the .bss section has a fairly high entropy, of 7.520; this is a great indication of encrypted data within the section, so we can go ahead and open it up in IDA, though first let’s examine the section in a hex editor, to confirm it is indeed encrypted.
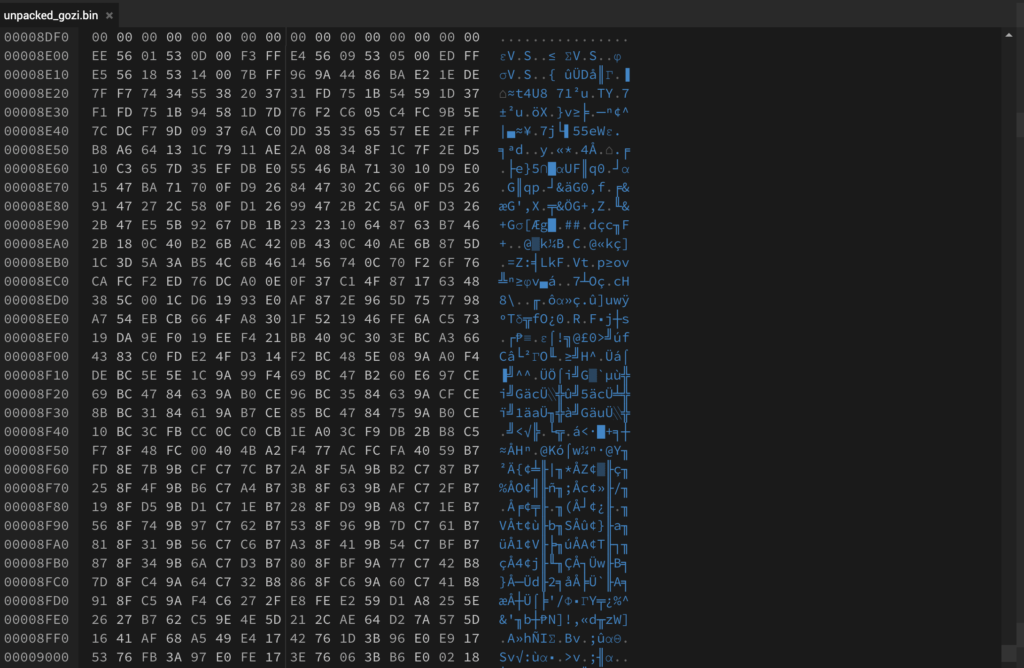
Opening the sample up in a hex editor and navigating to the .bss section we can see some clearly encrypted/encoded data. The encryption is basic, unlike RC4 or AES, as it seems to be quite repetitive, indicating the algorithm is a simple XOR or addition/subtraction operations. With this info we can assume the encrypted strings will be stored within this section, and we can now jump over to IDA to begin our analysis!
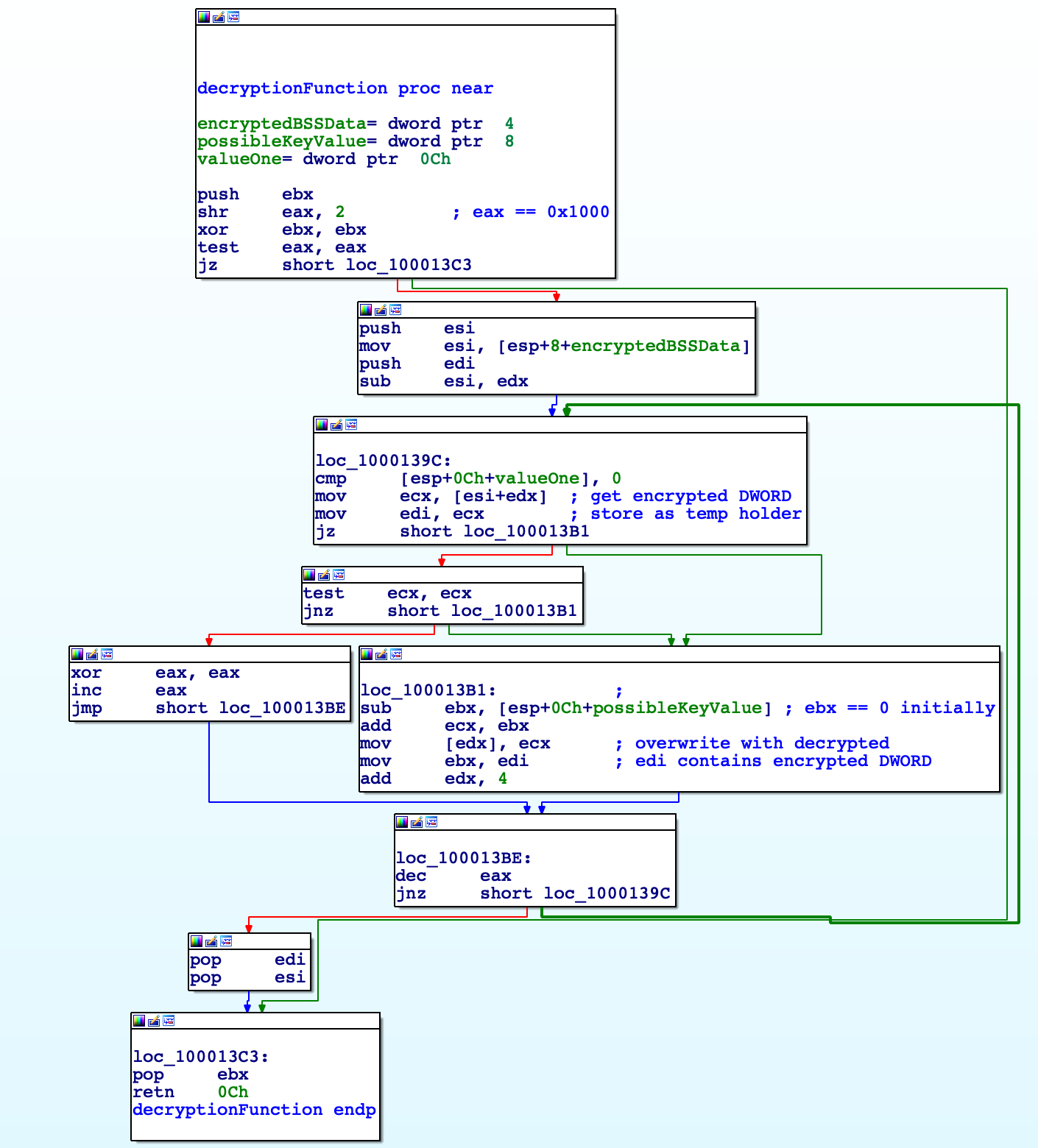
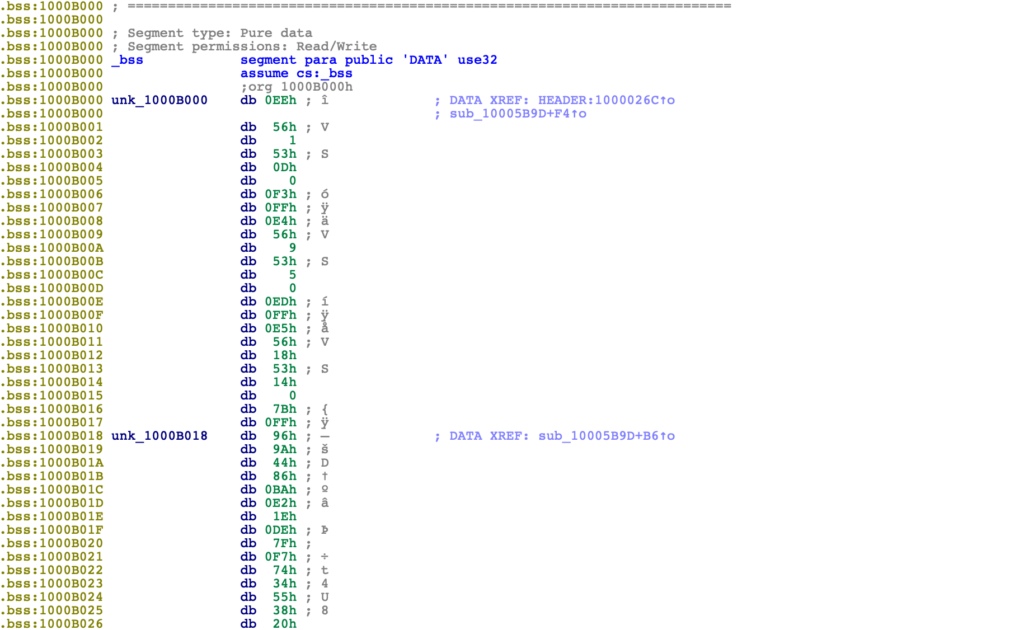
Checking out the .bss section inside IDA, we can confirm the data is definitely encrypted, and there are even several cross-references to data blobs within the code section of the binary (calls to GetProcAddress, LoadLibrary, etc.), so we can say for sure this is where the encrypted strings are stored. None of the cross-references are involved within a string decryption function however, so it’s likely the entire section is decrypted at once. Therefore, we will have to step through the first few functions of the entry point to try and find the function to decrypt the section.
After stepping through the first few functions, we come across a subroutine that references the string “ssb.”. Reversing that string we get “.bss”, and based on the initial [edx+0x3C], we can gather that this function will be parsing the binary to locate the .bss section. The reason the 0x3C is important to take note of is due to it being the typical offset of e_lfanew within the DOS Header. e_lfanew contains the offset of the NT headers, and so it is a crucial part of the parsing process. While this function doesn’t explicitly state edx is the base of the payload, we can jump out of this function and work our way up, tracing the contents of edx to confirm it is the base of the payload in memory.
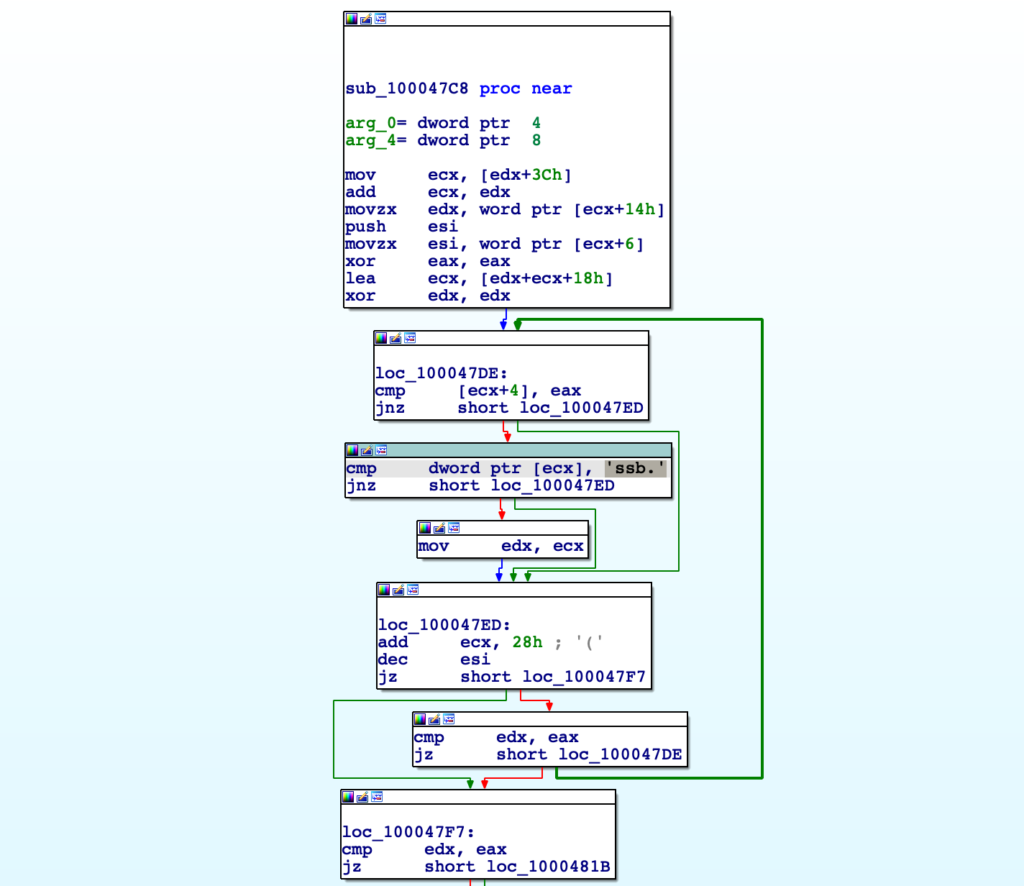
As a result, we will go ahead and import some standard structures into IDA so we can clean up the function by assigning different struct types. We’ll need to import IMAGE_DOS_HEADER, IMAGE_NT_HEADERS, and IMAGE_SECTION_HEADER.
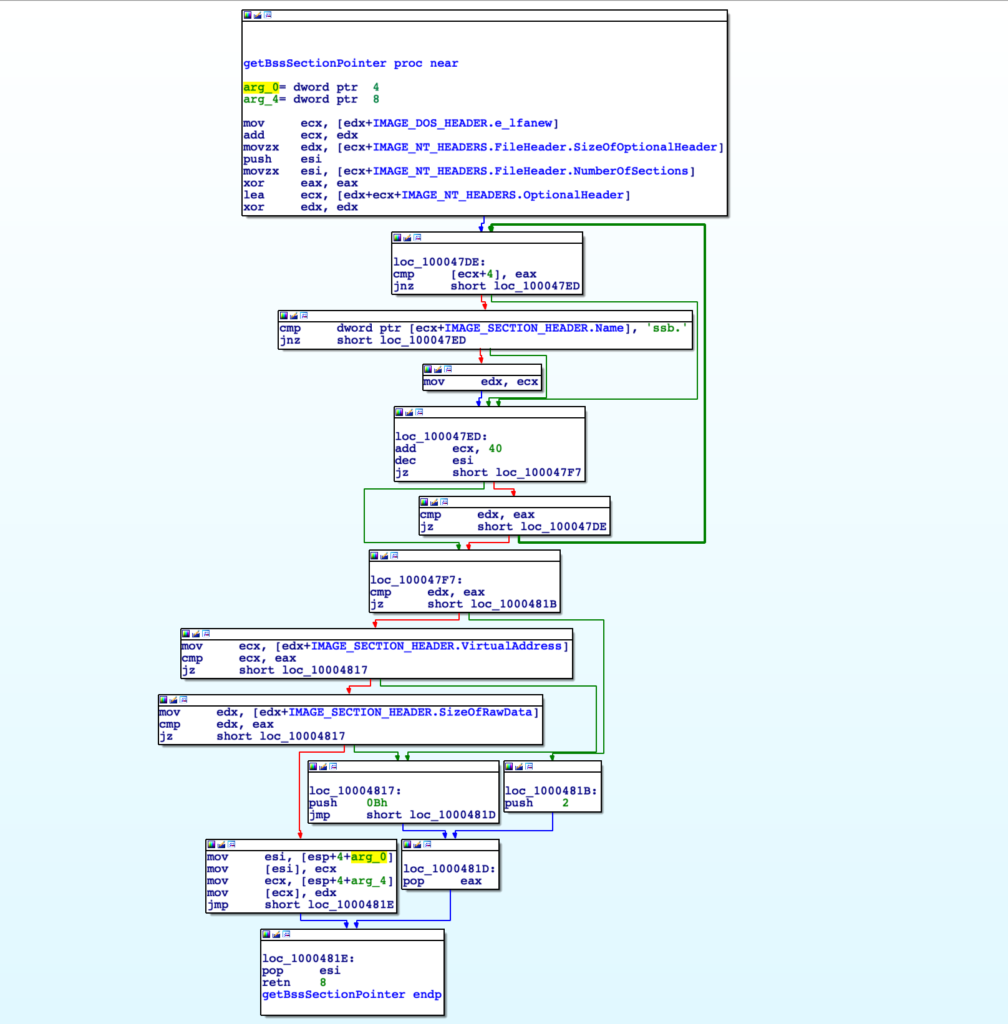
Now we can go through the function and assign the structure types accordingly by pressing T on each structure reference and selecting the most viable option. Once we’ve done this, we can clearly see arg_0 is going to contain the virtual address of the .bss section, and arg_4 will contain the size of the raw .bss section data. With this, we can jump out of this function and continue with our analysis.
We can see after the above function returns, a heap is allocated based on the size of the .bss section data, and this is promptly filled with the data from the .bss section. This is likely done to avoid overwriting the .bss section in memory, which is something important to take note of for later.

Continuing, after the memcpy call we have what seems to be some kind of a key creation block, based on a date. For those that have analysed Gozi/ISFB before, you’ll know this date indicates the date the campaign started.
In this key creation block, the first DWORD of the date “Apr 26 2022” is added with the second DWORD (essentially “Apr “ + “26 2”), before the virtual address of the .bss section is added. After that, arg_0 is added onto the calculations, before 1 is subtracted. This is then pushed to a function alongside the encrypted data, meaning we are most likely looking at the decryption function.
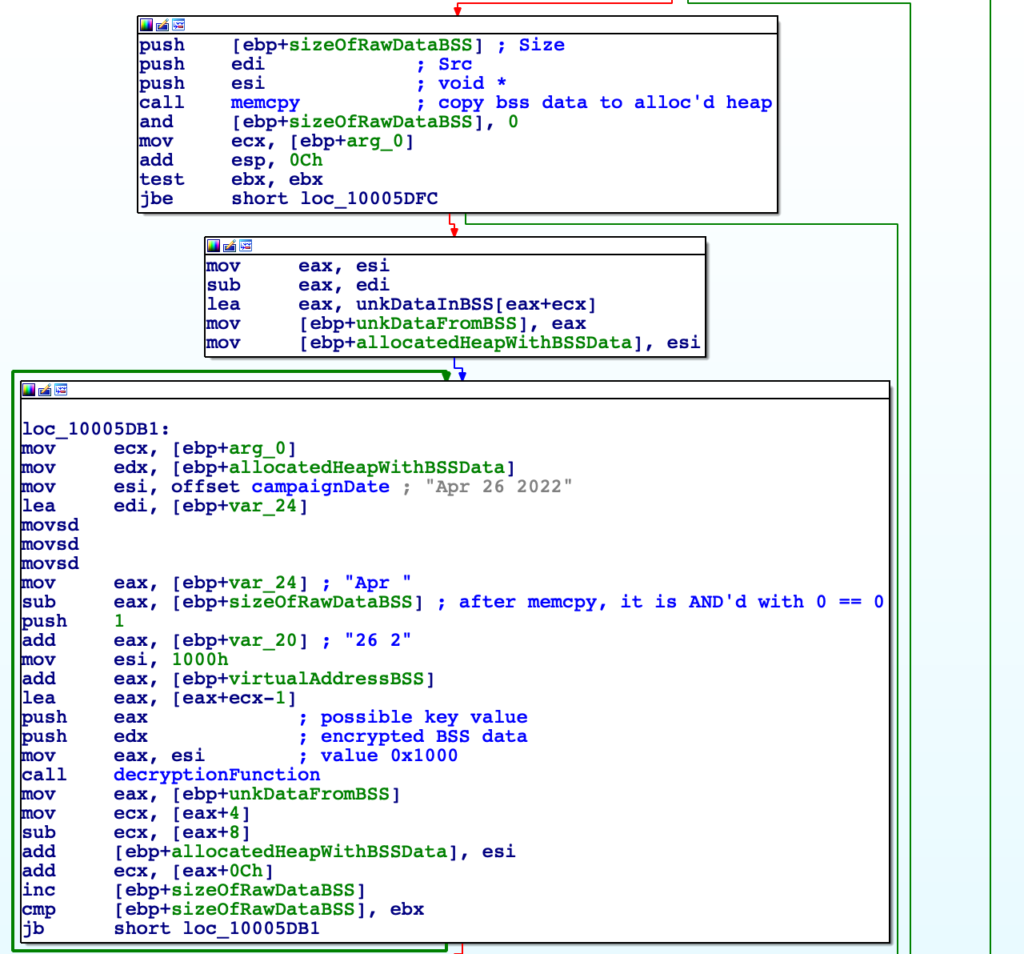
Before we do analyze the decryption function, it is important to figure out what arg_0 is. Jumping back, we can see prior to the core function being called, the system time is retrieved via an API call. Several operations are performed on this retrieved value, before being divided by the value 19, with the remainder being stored within eax. This will effectively return an integer between the value 0 and 18, which is then pushed to the decryption function. You may recognize this as being similar to the modulo operation, whereby performing a modulo 256 for example will give you a value between 0 and 255. We can also see that the function is in a loop, so it seems that the function will iterate multiple times until the right integer is returned from the _aullrem function, correctly decrypting the strings – almost like brute-forcing. This explains why the data is copied to a new region of memory, instead of being overwritten within the binary.
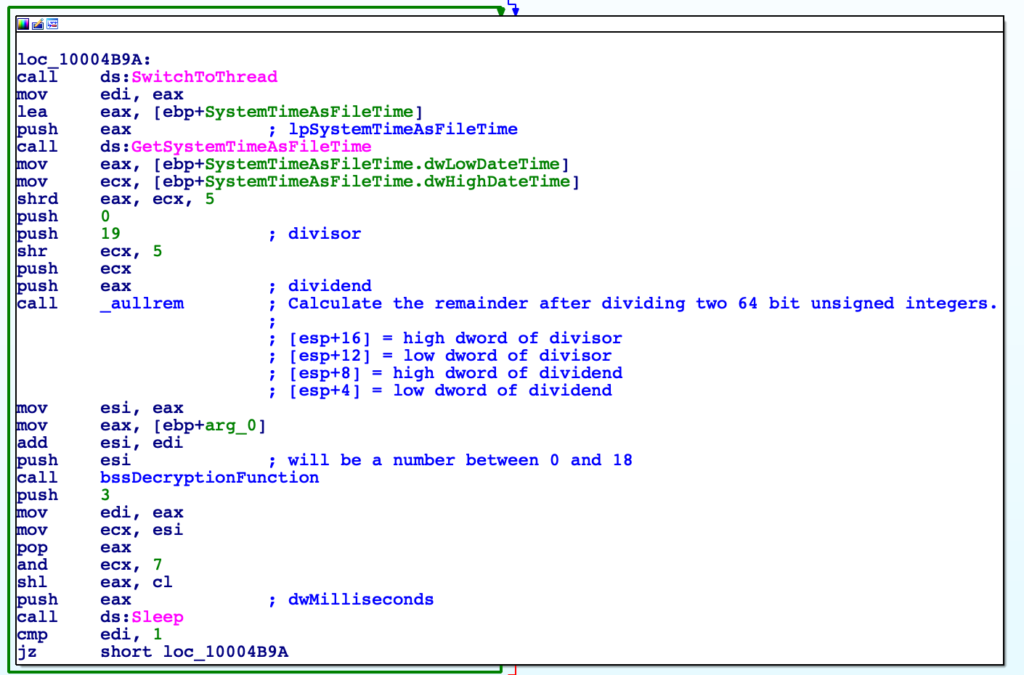
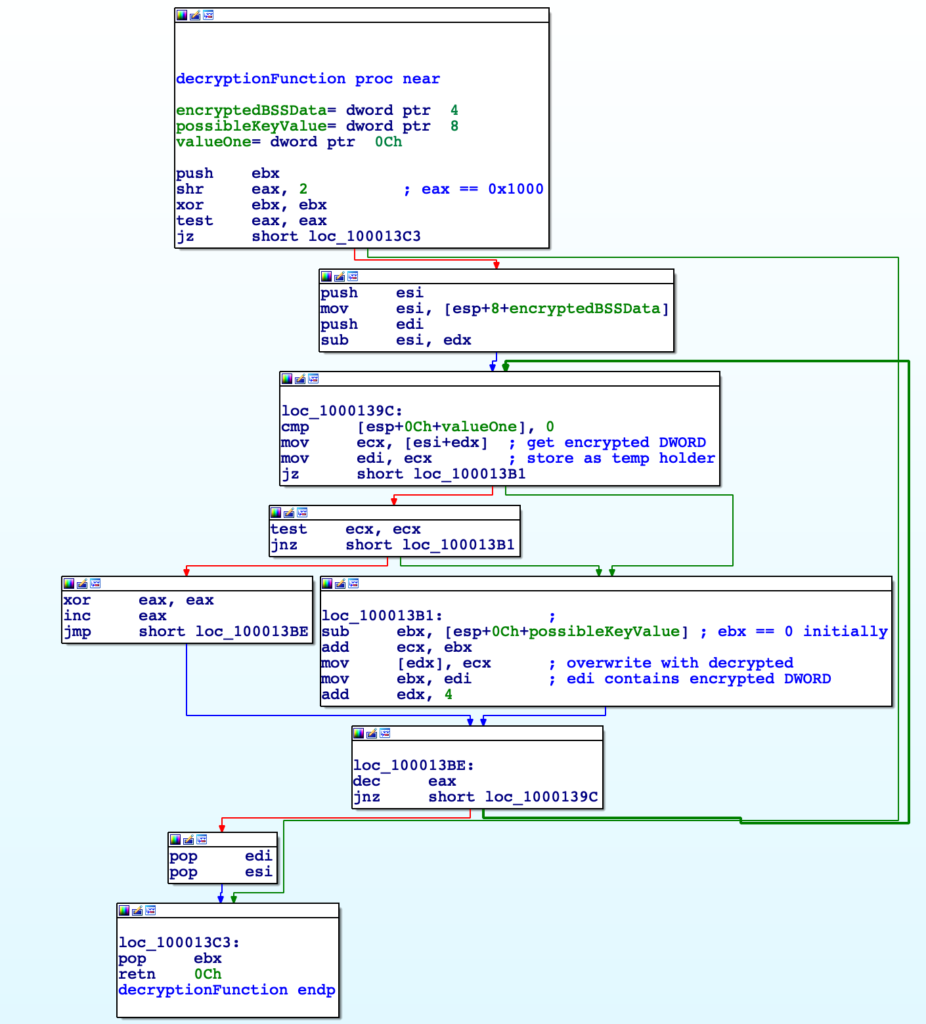
Now that we know the required values, let’s check out the decryption function. Luckily, it is simple, involving simple subtraction and addition, as well as using the encrypted data as part of the decryption function by storing them within temporary variables. It’s definitely a custom algorithm, though not too difficult for us to implement.
Implementation
So, now time for implementation! First things first, we will implement the decryption function itself. This is simple, as it just requires us to convert DWORDs to integer values, performing the calculation (subtracting the string key from the last encrypted DWORD and adding that to the current encrypted DWORD), and converting the result back to a DWORD. We can then add this to a decodedBytes variable, and simply iterate through the encoded data.
def decryptSection(stringData, stringKey):
lastEncoded = 0
decodedBytes = b""
for i in range(0, len(stringData), 4):
encodedBytes = struct.unpack("I", stringData[i:i+4])[0]
if encodedBytes:
decodedBytes += struct.pack("I", (lastEncoded - stringKey + encodedBytes) & 0xFFFFFFFF)
lastEncoded = encodedBytes
else:
break
return decodedBytes
Next, lets focus on the key creation. We will hardcode the campaign date for now, though will sort out some automation later. This is again fairly basic, just converting the string to integers, before adding them together, alongside the virtual address of the .bss section that we will get before using the PEFile module, and then adding someInteger – this is the system time integer that I will initially set to 1, and we can brute force later.
import struct
campaignDate = b"Apr 26 2022"
keyPart1 = struct.unpack("<I", campaignDate[0:4])[0]
keyPart2 = struct.unpack("<I", campaignDate[4:8])[0]
stringKey = keyPart1 + keyPart2
stringKey += bssVirtualAddress
stringKey += someInteger
With that, we can add in some parsing using PEFile to locate the .bss section. This is again simple enough, we just need to iterate through the sections, comparing each section name to .bss, and if a match is found we need to gather the virtual address and the pointer to raw data, which will allow us to read the entire .bss section and get the encrypted strings.
encryptedStrings = ""
isfbBinary = open(sys.argv[1], "rb").read()
print ("Analysing...")
pe = pefile.PE(data=isfbBinary)
for section in pe.sections:
if b".bss" in section.Name:
print ("Located encrypted string blob.")
bssVirtualAddress = section.VirtualAddress
bssFileAddress = section.PointerToRawData
encryptedStrings = isfbBinary[section.PointerToRawData:section.PointerToRawData + section.SizeOfRawData]
if not encryptedStrings:
print ("Failed to find encrypted string blob.")
return 1
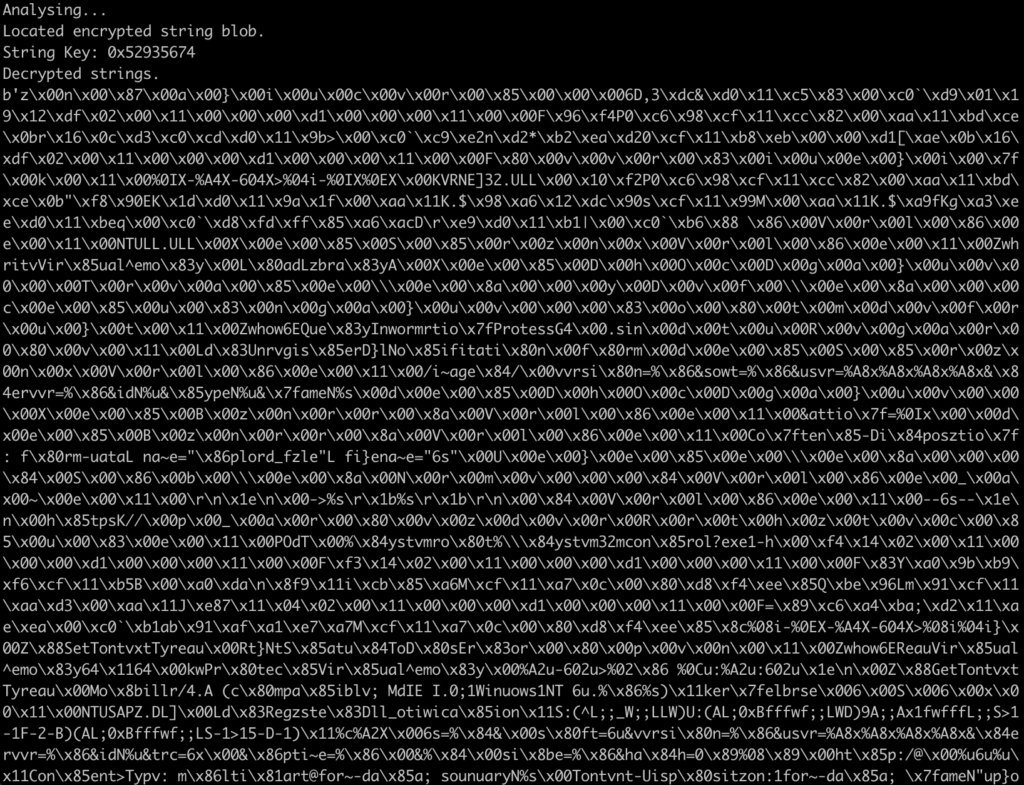
At this point, we can put all the code together, and run it! As you can see from the image below, we do get a strange output, not decrypted strings, though looking closely it is clear the strings are similar to what we’d expect, just slightly corrupted – for example NTULL.DLL instead of NTDLL.DLL.
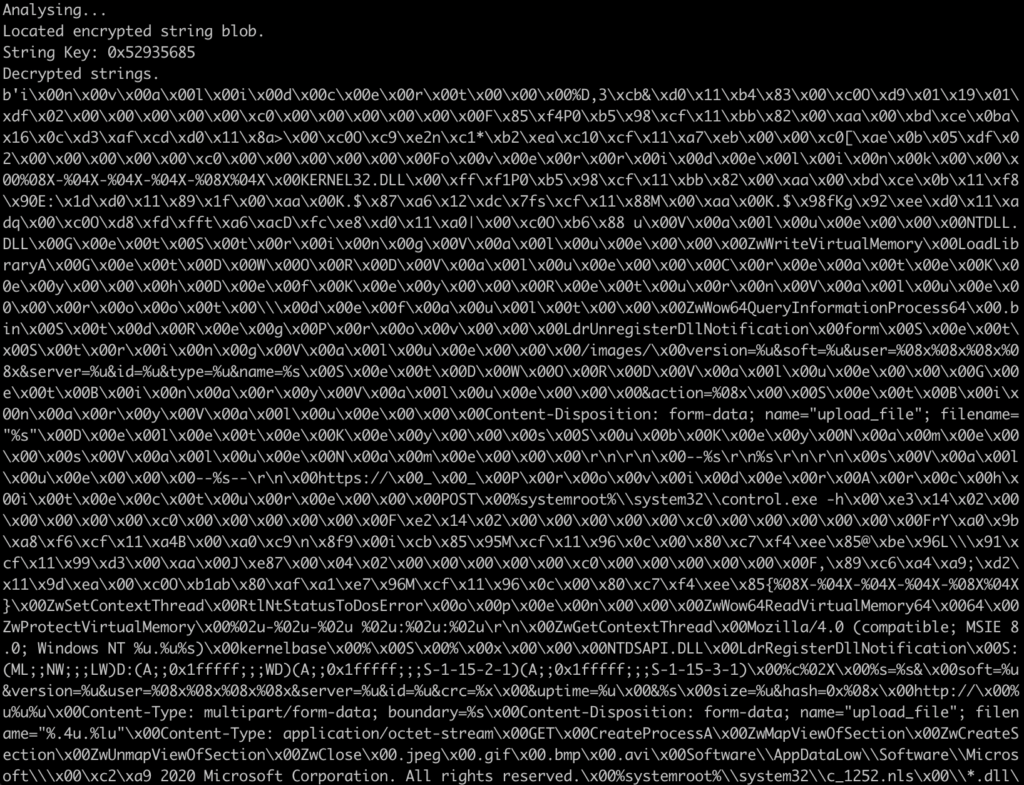
After some basic brute forcing (I just went ahead and changed the someInteger value until it worked out), we can determine the correct system time that is expected is the value 18. We could probably have subtracted the integer value of “U” from the integer value of “D” and got 17, and figured out quickly enough it was 18, or just brute forced the decryption automatically via a for loop, however I chose to manually do it – regardless we have now got the decrypted strings!
Before I do go ahead and overwrite the .bss section in the binary, I do want to automate the process of getting the campaign date. As the campaign date changes per campaign, it would be quite annoying to constantly have to run strings against a sample to locate the date. Therefore, I decided to implement some basic regex to locate the date. Using Regexr to test the rule, we can come up with an exact expression that should hit on every sample that contains a date in the expected format.
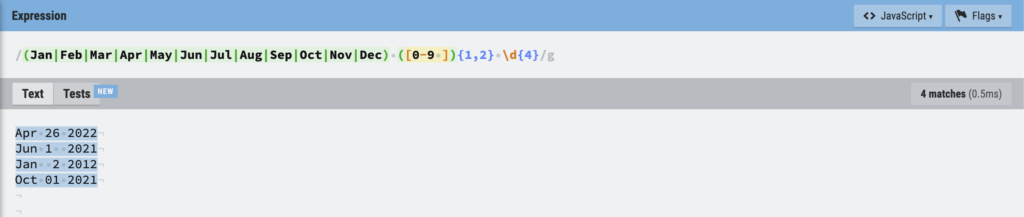
Implementing that in Python is easy enough, using the re module; we just search through the binary for the expression, and if a match is found we can extract the campaign date!
dateRegex = rb"(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) ([0-9 ]){1,2} \d{4}"
regexMatches = re.search(dateRegex, isfbBinary)
if not regexMatches:
print ("Failed to locate campaign date.")
return 1
campaignDate = isfbBinary[regexMatches.start():regexMatches.end()]
print ("Campaign Date:", campaignDate)
With that implemented with the rest of the script, we can now go ahead and run it once more, and it should be able to locate the date! This now should be automated for most ISFB v2 samples, assuming it is unpacked that is!
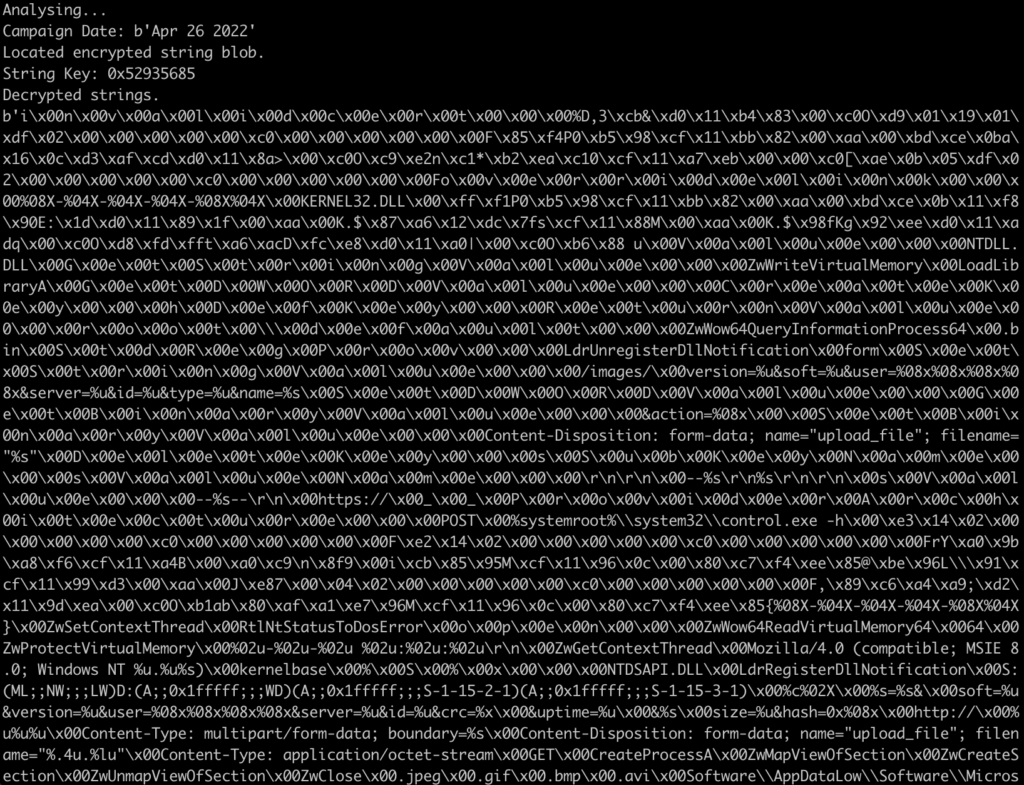
With that, all that is left to do is overwrite the .bss section, which can be done with the following one-liner:
finalBinary = isfbBinary[:bssFileAddress] + decryptedBytes + isfbBinary[bssFileAddress + len(decryptedBytes):]
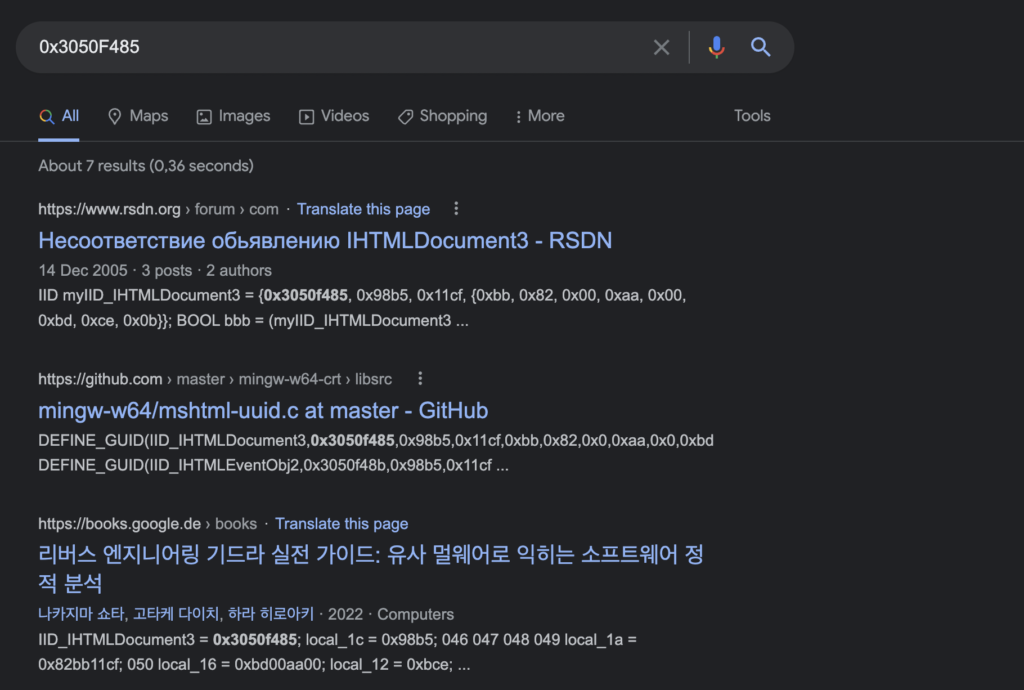
I chose to output the finalBinary to decoded.bin, so after running the script once more and opening decoded.bin within IDA, we can confirm that the decryption and patching was successful! If you are following along, you may notice some weird values near the top of the decrypted blob though – this isn’t more encrypted data, it is in fact COM CLSIDs.

Gozi/ISFB is a huge fan of using COM objects, and these CLSIDs are common within the decrypted section – a quick google search of a lot of the values will bring up a few references to COM objects and the purposes of each, making analysis a lot easier – this can get pretty confusing if you’ve never seen them, making them look encrypted still, but they are not.
And with that, we’ve now completed the challenge! The full code can be seen below, and feel free to share your write-up within the Discord channel or via your own blog post!
Make sure to keep an eye out for the next challenge!
Code
import binascii, sys, pefile, re, struct
def decryptSection(stringData, stringKey):
lastEncoded = 0
decodedBytes = b""
for i in range(0, len(stringData), 4):
encodedBytes = struct.unpack("I", stringData[i:i+4])[0]
if encodedBytes:
decodedBytes += struct.pack("I", (lastEncoded - stringKey + encodedBytes) & 0xFFFFFFFF)
lastEncoded = encodedBytes
else:
break
return decodedBytes
def main():
encryptedStrings = ""
isfbBinary = open(sys.argv[1], "rb").read()
print ("Analysing...")
dateRegex = rb"(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) ([0-9 ]){1,2} \d{4}"
regexMatches = re.search(dateRegex, isfbBinary)
if not regexMatches:
print ("Failed to locate campaign date.")
return 1
campaignDate = isfbBinary[regexMatches.start():regexMatches.end()]
print ("Campaign Date:", campaignDate)
pe = pefile.PE(data=isfbBinary)
for section in pe.sections:
if b".bss" in section.Name:
print ("Located encrypted string blob.")
bssVirtualAddress = section.VirtualAddress
bssFileAddress = section.PointerToRawData
encryptedStrings = isfbBinary[section.PointerToRawData:section.PointerToRawData + section.SizeOfRawData]
if not encryptedStrings:
print ("Failed to find encrypted string blob.")
return 1
keyPart1 = struct.unpack("<I", campaignDate[0:4])[0]
keyPart2 = struct.unpack("<I", campaignDate[4:8])[0]
stringKey = keyPart1 + keyPart2
stringKey += bssVirtualAddress
stringKey += 18
print ("String Key:", hex(stringKey))
decryptedBytes = decryptSection(encryptedStrings, stringKey)
print ("Decrypted strings.")
finalBinary = isfbBinary[:bssFileAddress] + decryptedBytes + isfbBinary[bssFileAddress + len(decryptedBytes):]
open("decoded.bin", "wb").write(finalBinary)
if __name__ == '__main__':
main()